Мониторинг домашней и серверной инфраструктуры на базе InfluxDB и Grafana
Возврат:: к списку статей мои статьи
Вступление, или не будем ждать проблем, когда они придут
В один не слишком прекрасный день я осознал, что то, что когда-то началось как одна Яндекс.Лайт-станция, за год превратилось в достаточно крупную и сложную распределенную домашнюю систему. В ней участвуют порядка четырех мини-серверов и пяти роутеров, разбросанных по трем локациям, а также нескольких удаленных серверов. В момент прозрения меня посетила мысль: нужно как-то контролировать всю эту инфраструктуру, следить за температурой (ведь лето близко!) и свободными дисковыми и оперативными ресурсами.
Изначально, когда я только начинал строить свой умный дом на базе Home Assistant, я старался втянуть в него всё, включая статистику. Однако со временем до меня дошло, что это не очень удобно (на каждой локации статистика собиралась в своем Home Assistant) и не слишком надежно (ведь HA не самая стабильная из всех систем, особенно при установке на базе Armbian). Более того, в умном доме не всегда нужны такие обширные данные, а то, что действительно важно, можно собирать более точечно.
Сразу оговорюсь, что я не считаю своё мнение единственно верным в данном вопросе. Большая часть моих знаний по администрированию основана на собственном опыте, который можно сравнить с хождением по граблям.
Требования к системе и результаты поиска
Мои размышления привели к тому, что я решил развернуть отдельную систему мониторинга для всей домашней инфраструктуры, и начали поиски...
Но сначала граничные условия:
- Использование docker. Я являюсь приверженцем использования docker контейнеров по максимуму так как это позволяет легко и быстро разворачивать и обновлять систему не заботясь о зависимостях.
- Легковесность. В планах было запустить основной (резервный, но об этом дальше) мониторинг на свободной железке tv-box под управлением armbian c 1Gb ОЗУ.
- Универсальность. Зоопарк систем не самый впечатляющий но он есть, и не хотелось сильно ограничивать себя в дальнейшем.
- Гибкость настроек, желательно с возможностью использования шаблонов.
Первый мой выбор пал на систему Zabbix, это профессиональный инструмент мониторинга серверов с гибкой настройкой и большим количеством возможностей. Но проблема Zabbix в его перегруженности, да это отличный профессиональный инструмент с большим количеством возможностей. В моих изысканиях я столкнулся со следующими проблемами:
- Развертывание в докере хоть и описано но работает очень плохо, приведенный вариант docker compose переусложнен и стартует не всегда (пробовал и в виртуалке Debian и на armbian), документация по установке докера хоть и описана но мягко говоря оставляет желать лучшего (не описаны некоторые очень важные параметры запуска docker compose для полноценной работы).
- Система тяжелая. Изначально я все разворачивал на своей мини машинке armbian и думал что проблема в первую очередь с ней, но даже при переезде на виртуалку с выделенными 2Gb озу Zabbix их съел и просил еще, а в тот момент был подключен только 1 сервер для мониторинга…
- Усложненные настройки и не самый очевидный интерфейс. Увы но мы живем в эпоху упрощения UI, и сотни настроек и параметров Zabbix для неподготовленного пользователя выглядят страшно.
- Zabbix agent в докере работает очень странно…
Следующим этапом стал новый поиск вариантов реализации, который привел к стеку Telegraf + InfluxDB + Garfana.
Скажу сразу данный вариант показался мне более интересным и удобным, не только из за красивой визуализации графаны (которую можно и к Zabbix прикрутить) но скорее из за возможностей InfluxDB.
InfluxDB — система управления базами данных с открытым исходным кодом для хранения временных рядов; написана на языке Go и не требует внешних зависимостей. Основной фокус — хранение больших объёмов данных с метками времени, и их обработка в условиях высокой нагрузки на запись
Я сразу разворачивал вариант на базе influxDB v2 которая в сравнении с версией 1 про которую написано больше всего материалов в сети намного, прям на очень много интересней. Да и это уже не только база данных а нечто большее…
После разворачивания influxDB поднимает web api и интерфейс, в котором можно:
- Управлять доступом
- Создавать и управлять корзинами (изолированными базами)
- Просматривать данные с помощью запросов и конструктора
- Настраивать уведомления путем запросов (в open source варианте доступно только slack и http из интерфейса, но есть способ отправлять и в телеграмм)
- Настройка дашбордов для мониторинга данных через запросы (или конструктором)
- Конструктор настроек для агентов сбора данных с возможностью хранения
- Красивый интерфейс… ну а куда без этого в наше время.
Немного примеров интерфейса:

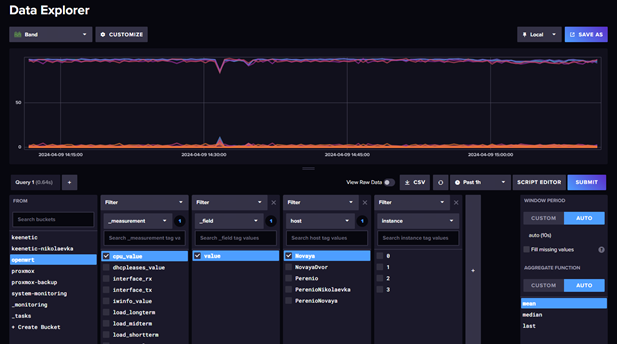
Общая схема работы системы
У influxDB в принципе очень хорошая документация, но вот примеры в других источниках в основном рассчитаны все таки на старую версию influxdb v1, в некоторых аспектах это может приводить к сложностям настройки, но в основном обратная совместимость осталась.
В принципе все системы мониторинга работают по похожей схеме Host -> Агент -> База данных -> Визуализация.
В данной системе influxDB является краеугольным камнем, а для него основной (и рекомендуемый) вариант агента является telegraf. Это удобный и универсальный инструмент который позволяет как собирать данные с текущего устройства так и выступать в роли некоего прокси который будет собирать данные с удаленных устройств и передавать их дальше (сразу в базу или в другие варианты вывода).
Grafana используется для визуализации и уведомления по условия, фактически при использовании influxDB v2 явной необходимости в ней уже нет, но под нее еще много удобных шаблонов так что пока пусть будет.
Сразу оговорю так как система распределенная я постараюсь уточнять что и где мы устанавливаем, но основная идея следующая:
- InfluxDB + Grafana установлены на сервере мониторинга (в моем примере 192.168.0.135)
- Агент для мониторинга серверов linux установлены на каждом наблюдаемом устройстве
- Агент в роли прокси (для сбора данных с роутеров) установлен на сервере мониторинга (но может быть размещен в любой точке сети)
Разворачивание и первоначальная настройка InfluxDB v2
Вступление получилось слишком долгим так что поехали. Начнем с установки influx + Grafana.
Для этого использую следующий docker compose шаблон:
version: '3.6'
services:
influxdb:
image: influxdb:latest
container_name: influxdb
restart: always
ports:
- '8086:8086'
volumes:
- /docker/influxdb/data:/var/lib/influxdb2
- /docker/influxdb/config:/etc/influxdb2
grafana:
image: grafana/grafana
container_name: grafana-server
restart: always
depends_on:
- influxdb
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
links:
- influxdb
ports:
- '3000:3000'
volumes:
- grafana_data:/var/lib/grafana
volumes:
grafana_data: {}
Обратите внимание что графана сохраняет свои файлы в volumes а не в монтируемые папки, только в такой вариации у меня получилось запустить ее с монтированием папок на диск.
Так же можно использовать дополнительные переменные для инициализации подробнее описано тут: https://hub.docker.com/_/influxdb Но я советую все же для удобства использовать первичную настройку.
Запускаем докер контейнер командой и заходим на веб интерфейс influxdb по адресу http://ServerIP:8086
Нас встречает приветственное меню Influx для первоначальной настройки

Заполняем данные, инициализации. Тут отдельно надо уточнить про поля организации и корзины. Фактически influx делит все ваши данные на изолированные базы на верхнем уровне организации и на более низком уровне корзины bucket, если проводить аналогии с первой версией bucket это старые вариации базы данных, именно в них попадают данные. При сборе данных нам будет важны эти параметры, но bucket можно спокойно создавать и удалять сколько надо из интерфейса.
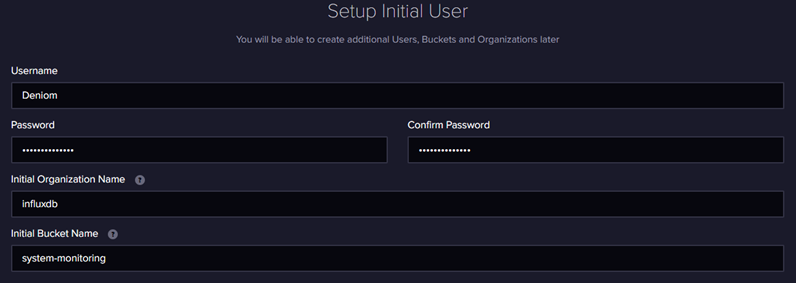
На следующей странице будет токен для api администратора, обязательно его сохраните это важно!!!
Обратите внимание кнопка копирования может не сработать!
Только с использованием токена можно работать через командную строку с базой, но токен можно сгенерировать новый через веб.
В принципе на этом вся настройка закончена… на главной странице есть инструкция как настроить использование influxdb cli (работает через api) и приведены инструкции и ссылки на документацию с видео.
Первоначальная настройка Grafana и подключение к InfluxDB
Заходим по адресу http://ServerIP:3000 где нас встречает окно авторизации. Если не были заданы пароль и пользователь по умолчанию при инициализации то заходим с данными admin\admin и меняем пароль.
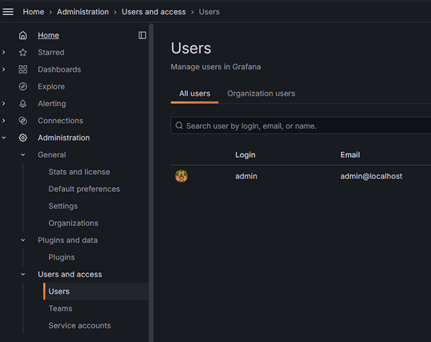
Для настройки пользователей переходим в раздел Administration – Users and access - Users
Для подключения Grafana к influxdb создаем токен доступа к корзине данных. Для этого возвращаемся в influxdb в меню идем Load Data – API Tokens и создаем Custom API Token даем ему право только на чтение (если не собираетесь запросами графаны менять данные) и даете понятное название. Больше нечего давать не надо. Сохраняем себе токен, он понадобиться для настройки Grafana.
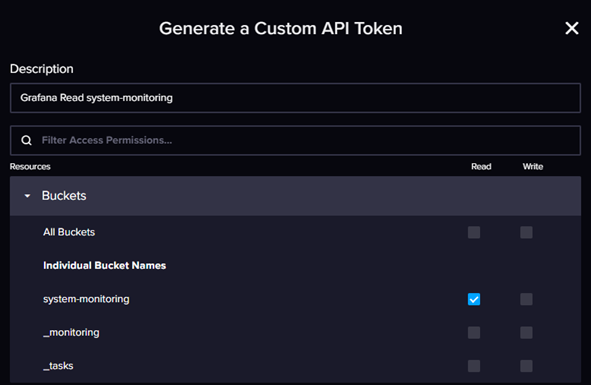
Обратите внимание кнопка копирования может не сработать!!!
Возвращаемся в Grafana и добавляем новый источник данных. Для этого переходим в connections и выбираем новый источник данных influxdb.
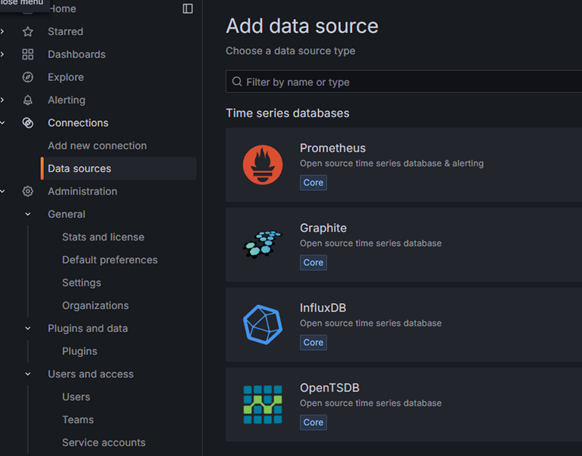
Вторая версия InfluxDB использует как основной вариант языка запросов flux но многие существующие шаблоны используют старый вариант на базе influxQL, но в самой Grafana при использовании такого варианта нет возможности авторизации по токену, а авторизация во второй версии является обязательной. Для этого необходимо отдельно добавит строку Custom HTTP Headers. Альтернатива использовать логин и пароль для InfluxDB Details, но это не рекомендуемый вариант.
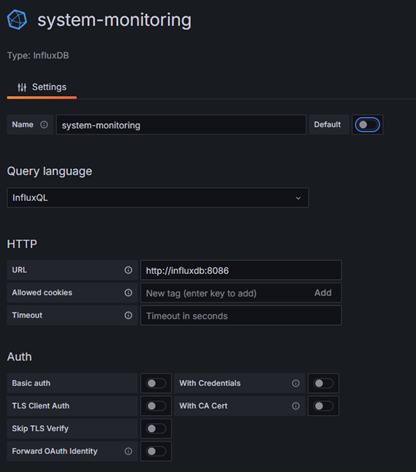
Заполняем настройки:
- Имя советую давать по именам корзин\bucket к которым даете доступ что бы не путаться.
- В поле url можно указать ip вашего сервера, но лучше использовать вариант с доменным именем контейнера.
- Авторизацию выключаем
- Добавляем Custom HTTP Headers в поле Header указываем Authorization в поле value пишем так: Token <ВашТокенДляЧтенияИзInflux> Пробел после Token обязателен
- В поле database указываем имя корзины
- HTTP метод GET
Ниже пример настроек:
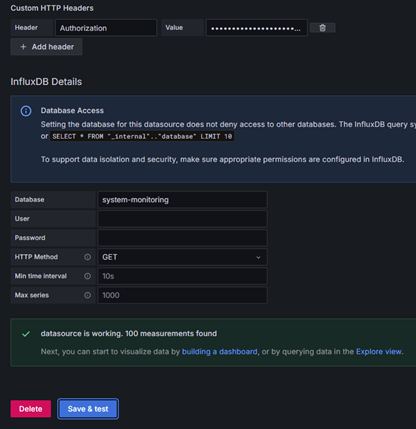
Для варианта с языком flux все несколько проще:
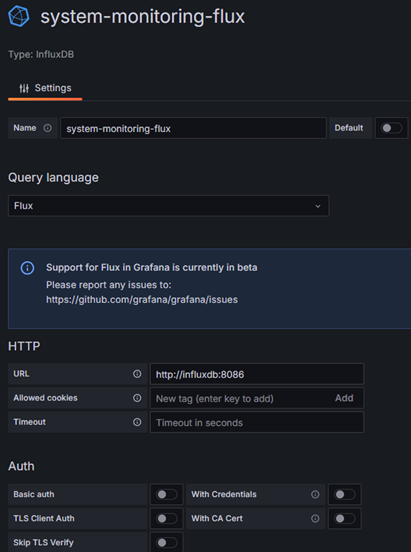
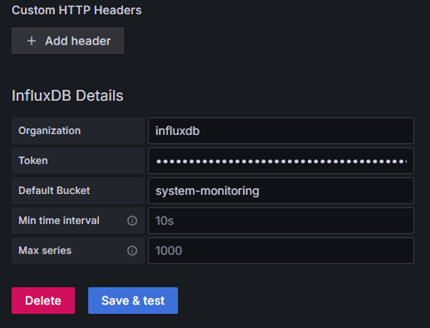
В поле токен пишем только сам токен без каких-либо дополнений.
Фактически настройка самой системы мониторинга на этом закончена дальше необходимо создавать дашборд панели и события, но нам все еще надо собрать данные о системе и с этим нам поможет telegraf.
Сбор данных о сервере с помощью telegraf
Перед запуском нам надо получить файл telegraf.conf в интернете есть достаточно много примеров о том как его составлять и подробно описаны какие модули есть, но нам на помощь снова придет influxdb v2.
Заходим в inffluxdb по адресу http://IPSerever:8086, нас интересует пункт меню telegraf
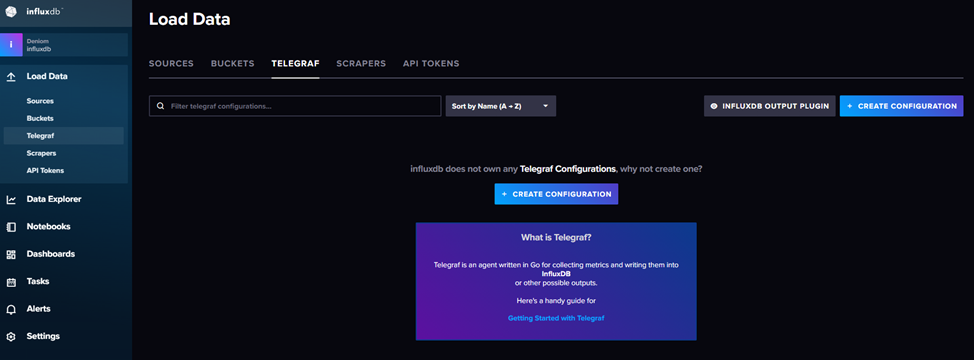
Создаем новую конфигурацию и выбираем что хотим собирать и куда складывать данные.
В конструкторе есть возможность выбрать только один вариант, так что нам придется его изменить.
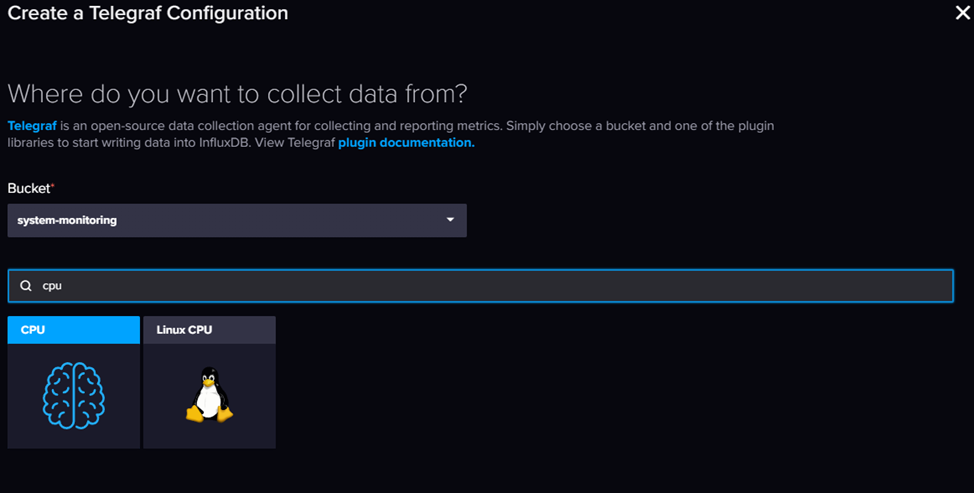
Получим шаблон настроек, который заменяем на нужный нам:
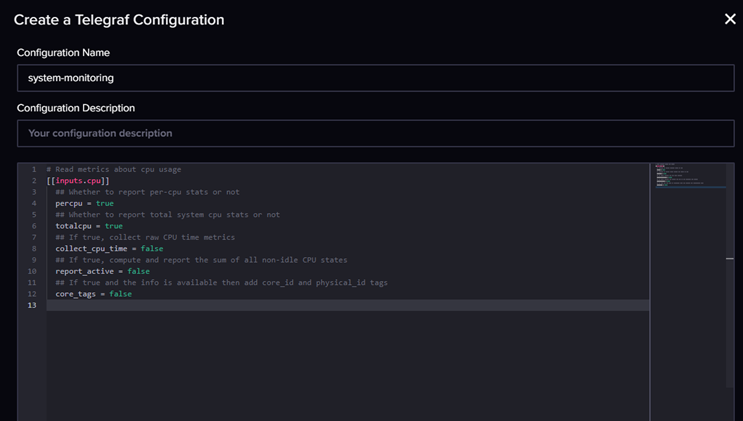
Текст шаблона для получения основных показателей:
[[inputs.cpu]]
percpu = false
totalcpu = true
collect_cpu_time = false
report_active = false
# Read metrics about disk usage by mount point
[[inputs.disk]]
## By default stats will be gathered for all mount points.
## Set mount_points will restrict the stats to only the specified mount points.
mount_points = ["/"]
## Ignore mount points by filesystem type.
# ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
[[inputs.diskio]]
devices = ["sd?", "nvme?", "nvme?n?"]
# Get kernel statistics from /proc/stat
#[[inputs.kernel]]
# collect = ["psi"]
# Provides Linux sysctl fs metrics
[[inputs.linux_sysctl_fs]]
# no configuration
# Read metrics about memory usage
[[inputs.mem]]
# no configuration
[[inputs.nstat]]
# interfaces = ["en*", "eth*", "ib*", "wl*"]
[[inputs.netstat]]
# no configuration
# Get the number of processes and group them by status
[[inputs.processes]]
# no configuration
# Read metrics about swap memory usage
[[inputs.swap]]
# no configuration
# Read metrics about system load & uptime
[[inputs.system]]
# no configuration
[[inputs.temp]]
# no configuration
Сохраняем после замены указав понятное название шаблону. Если мы планируем запускать без докера нам приводится инструкция как все быстро запустить.
Копируем себе токен из первого поля все что идет после export INFLUX_TOKEN=
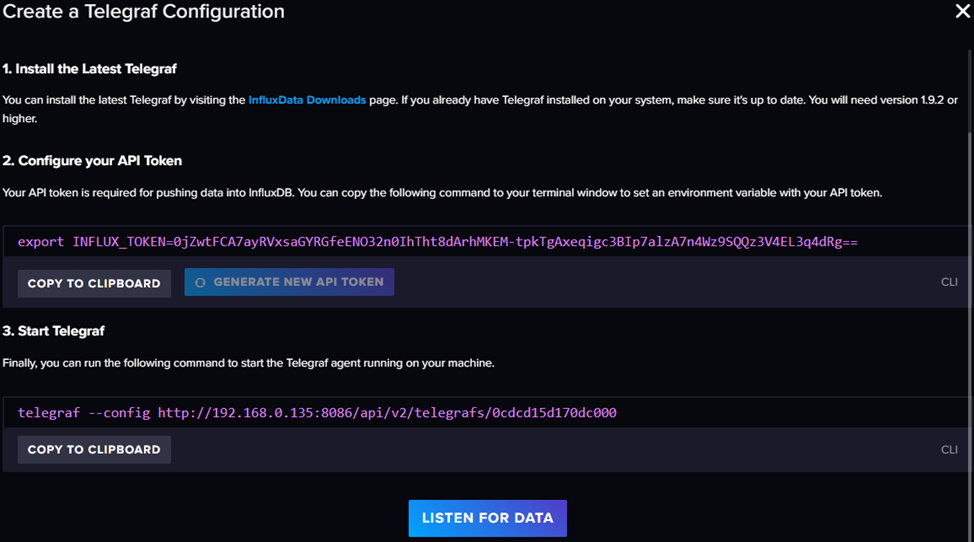
Почему мы используем этот вариант для докера если у нас не получиться быстро загрузить конфиг по ссылке? Все очень просто теперь у нас всегда есть заготовленный шаблон конфига в самой системе influxdb.
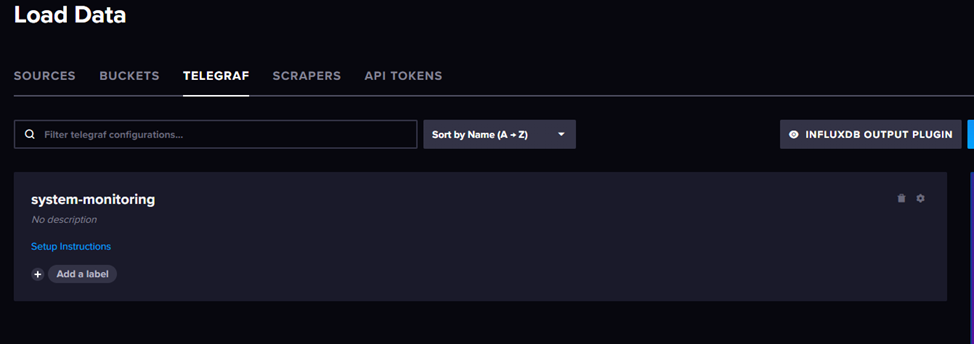
Нажимаем на название конфига и у нас открывается окно с полным шаблоном конфига, нам надо найти секцию [outputs.influxdb_v2] и в ней указать token который получили раньше. Формально это не рекомендуется и в продакшен все же так делать не стоит но у нас этот токен и так строго ограничен на запись одной конкретной корзины данных, так что пойдет.
Так же в конфиге надо указать hostname в секции [agent] для того что бы корректно различать с какого хоста нам поступили данные.
Сохраняем себе конфиг и идем на сервер, который хотим подключить. Нам надо поместить наш полученный файл по пути который указан в докере telegraf в моем примере /docker/telegraf/telegraf.conf
Важный момент выходов, как и входов у telegraf может быть несколько в том числе и однотипных. Таким образом мы можем одновременно передавать данные в две базы influxdb или, например публиковать на сервер mqtt для использования в системе умного дома.
Я в своей реализацию использую два сервера influxdb для сбора статистики одновременно, один для визуализации второй как резервная статистика на базе armbian tv box.
Создаем docker compose файл по шаблону:
version: "3"
services:
watchtower:
image: telegraf:latest
container_name: telegraf
environment:
- HOST_ETC=/hostfs/etc
- HOST_PROC=/hostfs/proc
- HOST_SYS=/hostfs/sys
- HOST_VAR=/hostfs/var
- HOST_RUN=/hostfs/run
- HOST_MOUNT_PREFIX=/hostfs
- TZ=Europe/Moscow
volumes:
- /:/hostfs:ro
- /docker/telegraf/telegraf.conf:/etc/telegraf/telegraf.conf:ro
После размещения конфига запускаем контейнер и проверяем что данные начали поступать в базу. Для этого идем в influxdb – data explorer
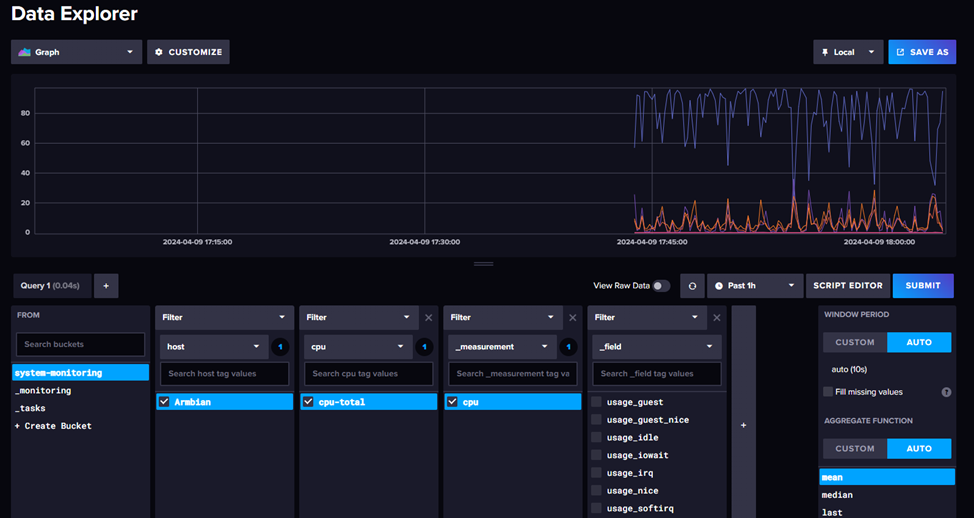
Все теперь данные собираются и пишутся в базу, а Grafana уже может эти данные получать и визуализировать.
Визуализация данных
Покажу визуализацию на примере шаблона https://grafana.com/grafana/dashboards/20762-telegraf-system-metrics/
Чаще всего в шаблонах описано все что нам надо, но в первую очередь обращаем внимание на источник данных если не уточняется то по умолчанию считается что надо источник influx v1 это первый вариант подключения.
Идем в меню Grafana пункт Dashboards
Создаем новый путем импорта шаблона, можно использовать или номер шаблона или json.
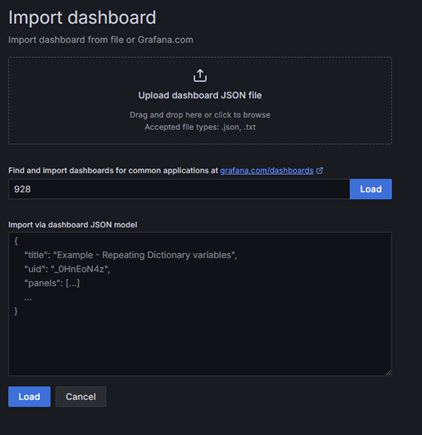
Указываем источник, для данного примера нам надо вариант обычный вариант
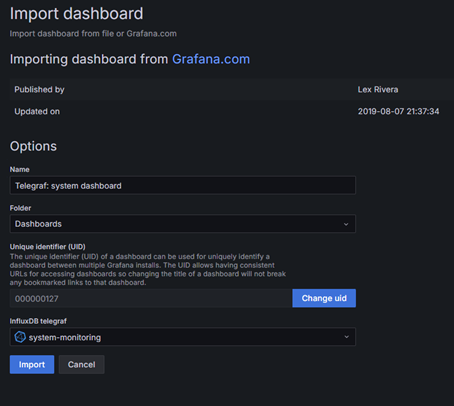
Вот и все мы молодцы и имеем красивую панель мониторинга со всей информацией по серверу
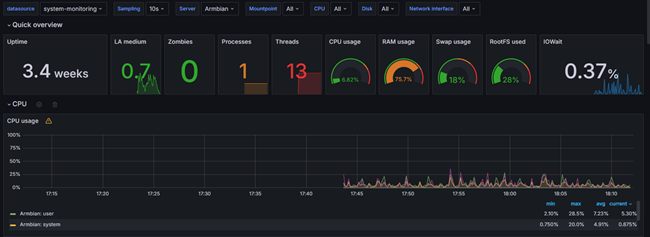
Несколько полезных советов по импорту:
- Если что то не работает в первую очередь проверьте в настройках импортируемого дашборада переменные что они корректно заданы под ваши настройки, иногда шаблоны не самого лучшего качества имеют захардкоженые имена корзин.
- Если хотите добавить новый блок удобней составлять запрос в Influxdb конструктором и взять от туда готовый вариант запроса для консоли.
На этом основные настройки закончены, из Grafana можно настроить уведомления по условиям запросов практически в любой меседжер. Можно бесконечно совершенствовать таблицу или объединять данные с разных серверов на сводную таблицу, возможностей уйма но основная задача данного материала это базовая настройка.
В дальнейшем расскажу как настроить мониторинг роутеров на базе keenetic и openwrt.
P.S. Делитесь хорошими и удобными панелями для Grafana или influxDB